Data Warehouse Modernization Initiative
The primary project goal is to improve our ability to maintain, and increase the quality of, the University’s custom and historical data assets to better support critical reporting, decision making, and predictive analytics.
Following an extensive RFP process, Plante Moran has been selected to help the University implement a solution leveraging Informatica and Snowflake that will:
- Implement modern tools for data processing and data warehouse management.
- Provide tools to strategically manage our data as we would any other high value asset.
- Develop a Data Catalog of definitions and robust Data Warehouse contents.
Evolution of the Data Warehouse
The Data Warehouse was initially created and is still known to this day as the Decision Support Database (DSD).
The Decision Support Database was created to generate and maintain the critical data sets required to support Institutional Research and reporting.
2017 - Data Warehouse Experiences End-of-Life Support Issues
- Production of consistent, timely data becomes limited from out-of-date and non-upgradable technology.
- Loss of institutional knowledge over time regarding data definitions or changes in how data was being entered or how data is used.
- Hand-coded warehouse management methods became unsustainable and complex.
2020 - Data Warehouse Adopts Shared Services Model
Executive Leadership committed to long-term support for the creation of a distinct Data Warehouse team, managed by a shared services governance model.
- Permanent staffing was increased from 1 to 2 FTE via broad system office reorganization.
- The Institutional Research Shared Services Committee (IRSSC) was formed, in which the 4 IR Directors equally participate in guiding and supporting the Data Warehouse functions.
- High-level goals were drafted:
- Continue to maintain the frozen data sets required by the four Institutional Research offices to generate reports and insights used in decision-making.
- Optimize resources by increasing common data sets, increasing automations, and centralizing the warehousing tasks common to all four Institutional Research offices.
- Promote consistency by upholding common, official, custom data definitions and applying data quality standards.
2021 - Needs Assessment and Gap Analysis Performed
IRSSC and the new Data Warehousing team began gaps analysis, examining our assets and needs compared to industry best practices.
- Industry trends in data warehouse methods and technology have seen dramatic improvements, offering significantly more advanced capabilities than the current system can support.
- Demand for data in standardized, refreshed, and ad-hoc formats exceeds current system capacity creating a strain on UA’s reporting resources both in technology and personnel.
- Authority and stewardship for data unclear, lack of policy and procedures.
- Increase in the number of data systems in use across UA equally increases the complexity of our data ecosystem and introduces significant challenges to orchestrating vast amounts of data in a unified and meaningful way.
2022 - Data Warehouse Modernization Project Initiated
The ETL, Data Warehouse and Data Catalog Project was initiated.
Research identified the following needs:
- A modern data Extraction, Transformation, and Loading (ETL) tool to help bring data from various sources into one location.
- A robust Data Warehouse management tool to ensure robust security, access, process automations, and to enhance data quality.
- A comprehensive Data Catalog to capture both shared and unique data definitions and the various critical reporting metrics across UA.
Issued an RFP seeking a technology platform to better manage our data assets across disparate data systems and silos, and to accommodate the University’s common and distinct business needs.
With support from OIT, each MAU IR office, and Procurement the Data Warehouse RFP was launched in September 2023.
- We received “a historically unprecedented number of inquiries” and “an unexpectedly large number of proposals” in response.
- The project scoring team is committed to thorough examination and comparison of the
diverse options proposed.
- In first quarter 2024 the scoring committee is working to identify a smaller, top-ranked group of 2-5 proposals.
- Scheduling a first round of demonstrations that will be technical in nature, focused on the ETL and data warehousing capabilities.
- Soliciting feedback from the broader UA community, inviting them to attend a second round of demonstrations focused on business-oriented elements of the data catalog and related reporting features.
Following an extensive RFP process, Plante Moran has been selected to help the University implement a Data Warehouse & Data Catalog solution leveraging Informatica and Snowflake. Implementation will likely involve;
- Redesigning the new Data Warehouse to include MAU-specific tables that reflect the local business practices of each University. University-level data can then be used to inform aggregated UA system-level tables.
- Focus on value-added data utility while addressing current challenges, such as increasing clarity and context of our data definitions, setting demarcation of historical/new warehouse data, and providing a common framework to support future system-level initiatives.
- The implementation is reliant upon; the capabilities/limits of the vendor product selected, the level of support and resources invested by UA, and our ability to balance current workload demands with the work efforts required to stand up a new system.
Significant pre-assessment and discovery activities to solidify scope, guide implementation, and identify potential expansion phases.
Project Summary Slide Deck

Welcome to an overview of the ETL, Data Warehouse, and Data Catalog Modernization Initiative.
The RFP launched in September of 2023 and is seeking a technology solution that will facilitate visibility and collaborative curation of our disparate data assets - beginning first and foremost with our Data Warehouse.

People and departments across the University make decisions every day that can impact the student experience. Each of these decisions, big and small, deserves trustworthy and timely data.
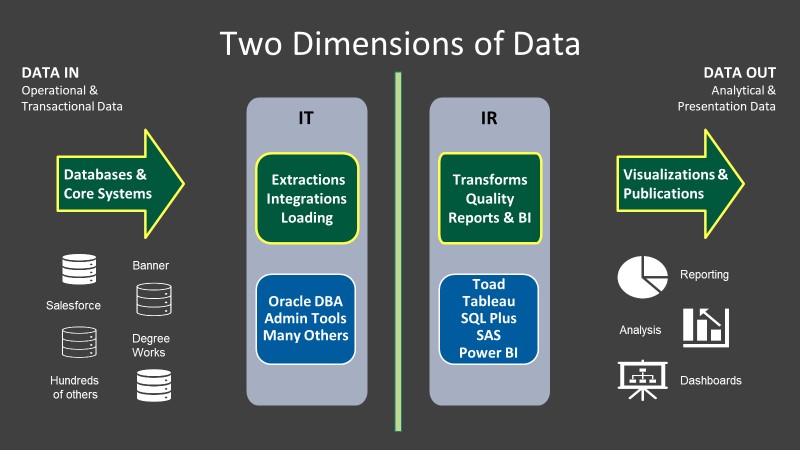
- DATA IN - Every aspect of the student experience is reflected in our data like a
mirror, moving and changing as they move through our system. This “live” data has
many names, production data, operational data, transactional data – reflecting real
time interactions and changes.
- DATA OUT - At the other end of the data spectrum, we also have reporting requirements. Some are imposed on us by outside entities such as federal and state offices (IPEDS). Other data we’ve deemed as critical to support the decisions we make every day – all with the goal to improve the student experience. This can be referred to as analytical data and it resembles a picture, a snapshot of the data is frozen and saved on a schedule to provide stable reference points.
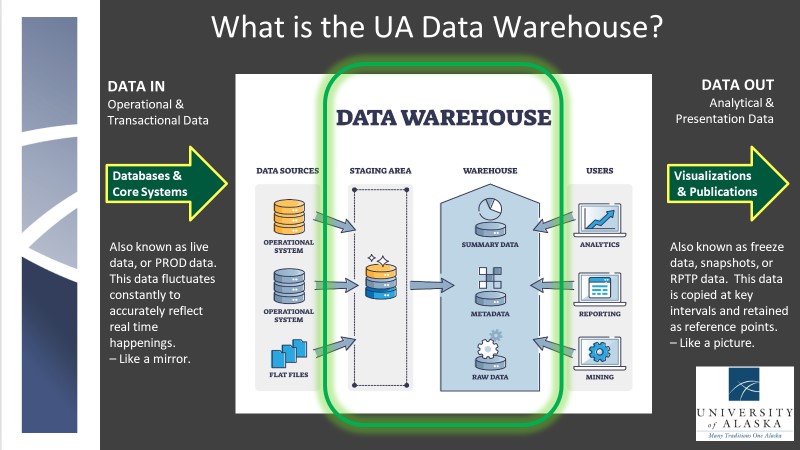
Have you ever…
- Used a report that pulls data from DSDMGR?
- Run a report from Qmenu or QAdhoc?
- Pulled data from a “freeze” table?
- Used TOAD to query something in RPTP (now RPTP On-Prem)?
- Visited one or more of the Universities IR Enrollment Dashboards?
- Read the UA in Review report?
Then you are a Data Warehouse user!

As the IRSSC and the new Data Warehousing team was formed, we began to examine our assets and identify areas of need as compared to modern data warehousing standards and industry best practices.
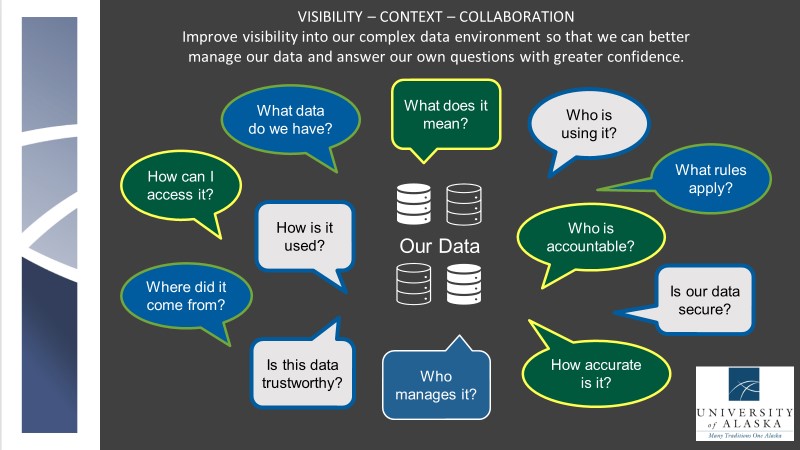
- We lack a platform to view and manage data across multiple data systems, content area silos, and varying campus business needs. Frequently resulting in multiple answers to the same data question.
- Increasing demands for trustworthy data and timely insights creates a strain on reporting resources to meet the demands. (80/20 rule)
- Data Warehouse created circa 1999. The same tools & methods are used today and are unsustainable as they reach end-of-life.
- Quality of data unknown, loss of institutional knowledge over time regarding data meaning and changes in data use.
- Authority and responsibility for data unclear.

Imagine this work multiplied across our system, all the people and departments grappling with data to perform their work and to drive decisions.

Most data warehousing products available today offer additional capabilities that extend beyond the scope or purview of the UA Data Warehouse. Such as an enterprise-wide data lake house, fabric, or mesh. Or a data governance platform intended for the larger University community to collaborate in the management of our data assets.
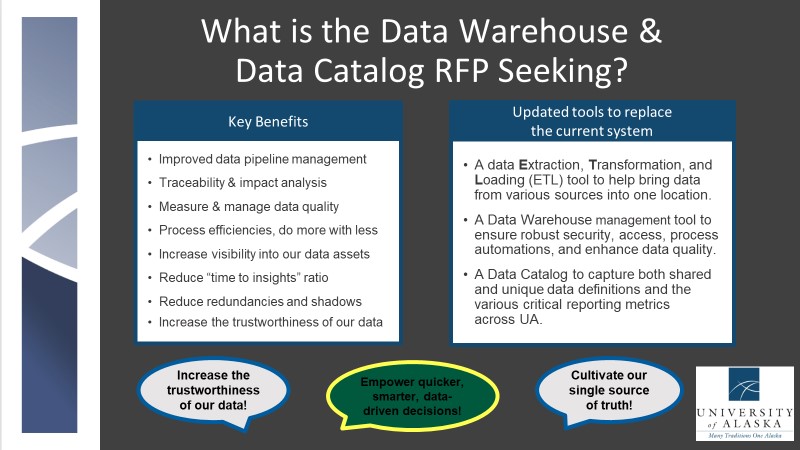
The three primary capabilities sought are:
- A data Extraction, Transformation, and Loading (ETL) tool to help bring data from various sources into one location.
- A Data Warehouse management tool to ensure robust security, access, process automations, and enhance data quality.
- A Data Catalog to capture both shared and unique data definitions and the various critical reporting metrics across UA.
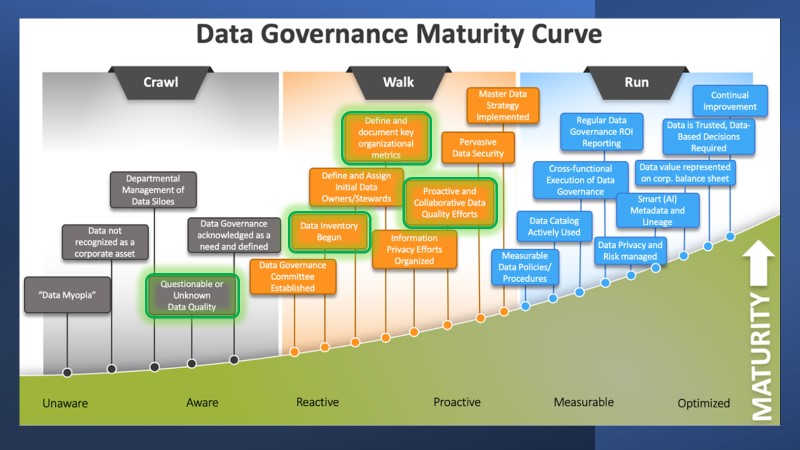
- The green boxes highlight areas where new ETL, Data Warehousing, and Data Catalog tools could help the University advance in the strategic management of our data assets.
- This chart also brings to light other milestones that could advance our data governance maturity level. These lie outside the scope of the project and the beyond the purview of the Data Warehouse.
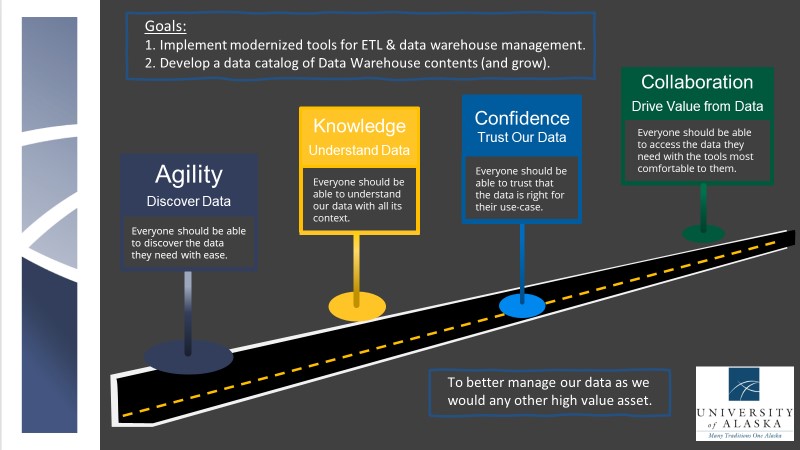
- Potential usefulness extends beyond “just IR”. Data Catalogs and accompanying platforms for self-service analytics could be used by everyone in the UA system, customizable to their distinctive data needs.
- New tools will allow us to take measure of our data quality (even if it’s terrible) and allow us to set micro-goals or apply logic or cleansing rules to improve the quality of our data.
- Being able to find our data, know its quality, and understand its context will help increase the trustworthiness of our data – for the benefit of everyone, including our students.
- Modern data tools can connect with a wide variety of data sources to provide a data catalog unified across not only data “silos” but disparate data systems as well.

For more information contact UA-IR-DataWarehouse-Team@alaska.edu